第5回解説 解1 (solution1.scala)
Solution1 オブジェクトは Solution trait です
前節で述べたように,Solution1オブジェクトはSolution traitが求める機能をすべて提供しています.このため「Solution1オブジェクトはSolution traitだ」と見做したいのですが,この考え方は自動的には定まらず,わたしたちが明示してやらなくてはいけません.
「あるオブジェクトがtraitである」ことを明示するためのいくつかの方法のうち,Solution1.scalaでは以下の形式の最も簡易な方法を採用しています.
object Solution1 extends Solution {
...
}この例のようにobject宣言にextends宣言を追加することで,Solution1オブジェクトがSolution traitと見做せることが宣言できるのです.
ところで,オブジェクトが複数のtraitと見做しうる場合もあります.むしろ,そういう場合のほうが普通です.たとえば,Scalaの標準ライブラリのドキュメントでListを調べてみると,なんとこれが,5つのtrait (LinearSeq, Product, GenericTraversableTemplate, LinearSeqOptimized, java.io.Serializable)と見做せることがわかります.実は,これらのtrait自体がほかのtraitを包含しているために,List型は以下のさまざまな型として見做しうることがわかります.
- ListSerializable
- LinearSeqOptimized
- Product LinearSeq
- LinearSeq
- LinearSeq
- LikeSeq
- Iterable
- Traversable
- Immutable
- AbstractSeq
- Seq
- SeqLike
- GenSeq
- GenSeqLike
- PartialFunction
- Function1AbstractIterable
- Iterable
- IterableLike
- EqualsGen
- IterableGen
- IterableLike
- AbstractTraversable
- Traversable
- GenTraversable
- GenericTraversableTemplate
- TraversableLike
- GenTraversable
- LikeParallelizable
- TraversableOnce
- GenTraversableOnce
- FilterMonadic
- HasNewBuilder
- AnyRef
- Any
このように一般にオブジェクトは複数のtraitと見做すことができるのですが,残念なことにSolution1で用いた簡単な方式では,オブジェクトにたったひとつのtraitしか割り当てることができません.複数のtraitを与えたい場合にはextendsではなく,with宣言を用います.たとえば,List型の場合,以下のように宣言されています.(注:ここで用いられているclass宣言は,object宣言とよく似ています.object宣言の目的はオブジェクトを生成することなのですが,class宣言はオブジェクトを生成するための雛形(クラスと呼びます)を宣言することにあります.クラスを用いることで,オブジェクトの複製を作れるようになります.)
sealed abstract class List[+A] extends AbstractSeq[A]
with LinearSeq[A]
with Product
with GenericTraversableTemplate[A, List]
with LinearSeqOptimized[A, List[A]]
with java.io.Serializable {
...
}Scalaにおいて,オブジェクトがtraitを満たすことを宣言する方法には以下があります.
標準ライブラリと公式ドキュメントの読み方
さきほど紹介したScalaのList型の公式ドキュメントを眺めてみましょう.頭がクラクラすると思います.英語ということではなく,List型が提供する機能の数に.ひと通り,上から下まで眺めまわして下さい.表のなかでdefで始まっているものがList型が提供している機能です.わたしが勘定したところ,全部で166個もありました.わたしもクラクラしてきます.「全部,覚えなさい」などとは言いません.
これらのメソッドのほとんどはtraitに由来するものです.Scalaの公式ドキュメントは非常によくできていて,traitを選択することで,プログラマの関心に応じた機能を効率的に見つけられるようになっています.公式ドキュメントのわりあい最初の方に以下のパネルが見つかると思います.
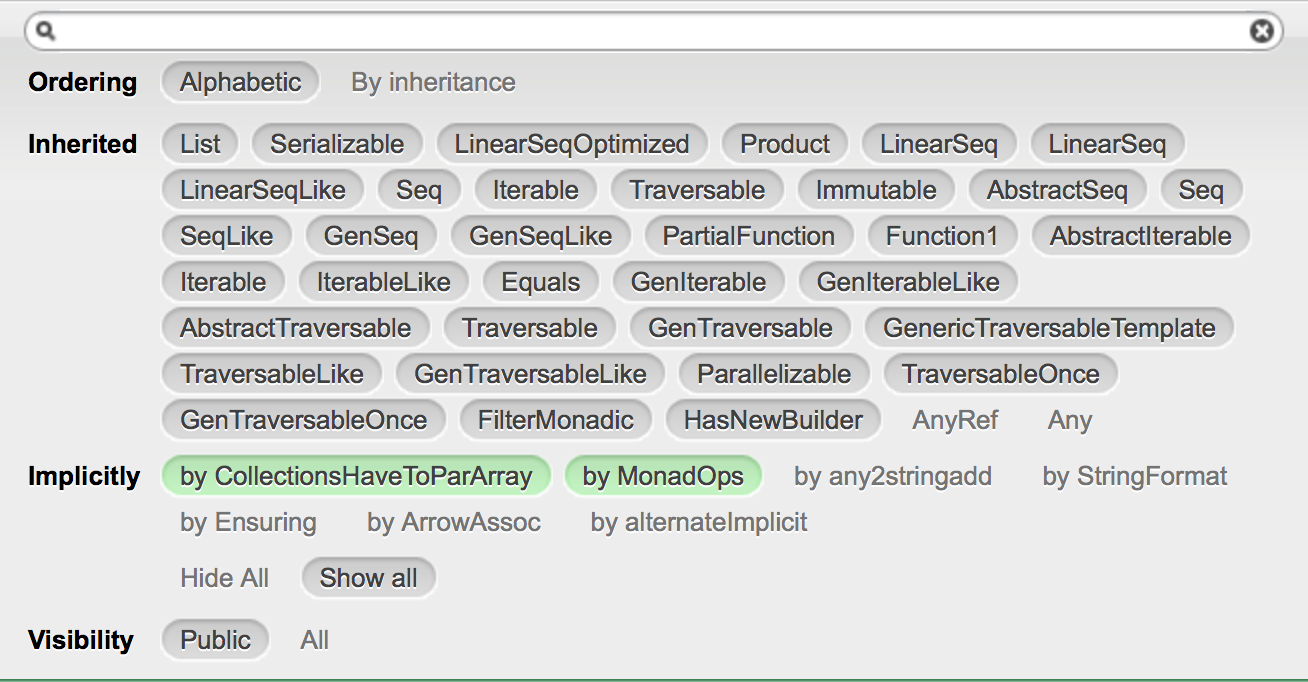
ここで,InheritedのところにList, Serializable, …, HasNewBuilder, AnyRef, Anyが掲載されています.これらはtraitなどを用いてList型の機能を分類したものです.このうち,AnyRef と Any 以外は灰色で塗られています.ここだけ眺めていてもわかりにくいのですが,灰色は選択状態を意味し,AnyRef や Any のような状態は選択されていない状態にあたります.
Visibilityの欄の上に,Hide AllとShow allがあり,元々は後者が選択されていることがわかるでしょうか.ここで,Hide Allをクリックしてみましょう.すると,表に掲載された機能の数が今度は,わずかなものになることがわかりますでしょうか.このなかには,foldRight, foreach, map, reverse, slice, takeのような基本的なリスト処理のメソッドが残っています.
Hide All状態では24個の機能だけが表示されます.これらの機能はList型が直接的に提供しているものです.逆に最初に見ていた166個の機能のほとんどはList型がほかのtraitから貰い受けている機能だということになります.
さきほどはInherited欄でAnyRefとAny以外が選択されていましたが,Hide Allの状態ではListのみが選択されています.ところで,この状態ではfoldRightは見えるのに,foldLeftはないことに気づきましたか?foldLeftはLinearSeqOptimized traitが提供しているようです.LinearSeqOptimizedをクリックするとfoldLeftが現れます.LinearSeqOptimizedのLinearSeqとは線形走査を意味します.Optimizedは最適化を施して,処理が高速化されていることを意味しています.つまり,List型が提供する線形走査のうちで特に高速化されているものがLinearSeqOptimized traitに整理されているのです.
166個の機能の数も膨大なのですが,Inheritedで見える機能カテゴリも37個もあり,やっかいです.これらをもう少しざっくりと理解するには型階層の図が便利です.機能分類の図の上にあるType Hierarchyをクリックしてみてください.
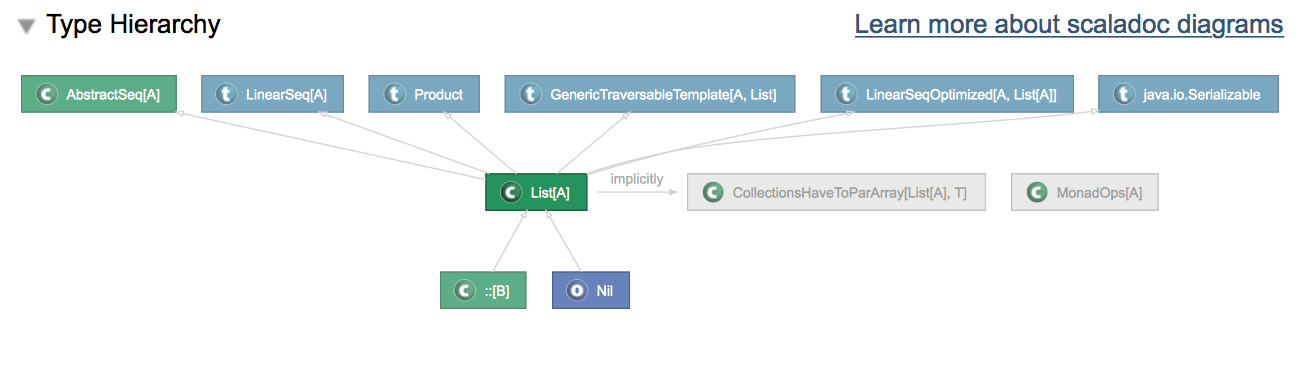
ここに表示されたものが,List型にとって特に重要なことがわかります.
- AbstractSeq[A]
- LinearSeq[A] — 破壊的な代入を禁止したリスト構造を表すtrait.十分効率的なhead, tail, isEmptyの提供を保証します.
- Product — 直積の構造を表すtrait.リストは (head: A) と (tail: List[A]) の直積で表現されるため,Productとなっているようです.
- GenericTraversableTemplate[A, List]
- LinearSeqOptimized[A, List[A]] — さまざまなリスト処理のメソッドを提供するtrait.効率的な isEmpty, head, tail の実装が利用できることを仮定している.
- java.io.Serializable — 線形化 (Serialization) とは,メモリ内のデータ構造を一連のデータ列に変換する処理を意味しています.データ列に変換することで,元のデータ構造をファイルに保存したり,通信することができます.この機能は,Scalaの基盤となっているJavaで実装されています.
これらのtraitたちの注釈は,traitをクリックして概要の説明を読めば理解できます.さて,ここまで理解すれば,主要なリスト処理機能を知りたければLinearSeqOptimizedに由来する機能を調べればよさそうなことがわかりますね.
実際に,一旦,Hide Allを選択したのちにLinearSeqOptimizedを選択すると,contains, drop, exists, find, flatMap, foldLeft, forall, foreach, last, length, map, reduceLeft, reverse, slice, span, splitAt, takeなどといった,馴染み深い機能に絞り込むことができ,当初の情報過多な状況から脱することができます.
安心したところで,solution1.scalaで最初に用いられている標準メソッド(nums.foldLeft)の機能を調べてみましょう.この標準メソッドがList型が提供していることは,numsの型がListであることからわかります.そこで,List型についての公式ドキュメントの画面で,LinearSeqOptimizedのみを表示した状態でfoldLeftの解説を探すと以下のような簡単な説明が表示されます.

このメソッドの入出力の型と二行足らずの説明しかなく,かなりおおざっぱな概要しか見られないですね.でも,この解説の左の方にある右向き三角をクリックすると,もっと詳しい解説を読むことができます.

solution1.scala で用いた,細かい技法
標準ライブラリとそのドキュメントの読み方を学んだので,それを頼りに solution1.scala を眺めなかがScala言語についての理解を深めていきましょう.
Curry化したメソッド
solution1.scalaの18-20行目に以下のメソッド定義があります.もしかして,見慣れない定義でしょうか.
def c(n: Int)(nums: List[Int]): Int = {
nums.foldLeft (0) ((s, x) => s + (if (x == n) 1 else 0))
}この例では2引数のメソッドcを定義しています.ただ,def c(n: Int, nums: List[Int]) ... ではなく,def c(n: Int)(nums: List[Int]) ...という形式で定義しています.この場合,cはふたつの実引数の値をタイミングをずらして取得することができます.実際にScalaのインタプリタを用いて,このメソッドの型を調べてみましょう.
scala> def c(n: Int)(nums: List[Int]): Int = {
| nums.foldLeft (0) ((s, x) => s + (if (x == n) 1 else 0))
| }
c: (n: Int)(nums: List[Int])Int
scala> c _
res0: Int => (List[Int] => Int) = <function1>
これよりcがInt型の値をとって,関数を返す高階関数だということがわかります.これにより,nとnumsのうち,前者の値のみが定まっているときにc(n)によって残りのnumsを得て,計算をする関数を作ることができます.
val c1 = c(1) _さっき,$c$の型を調べるときに単にcを入力すると以下のようにエラーになります.
scala> c
<console>:12: error: missing arguments for method c;
follow this method with `_' if you want to treat it as a partially applied function
c
^
「関数に引数は渡さなくていいの?本気で関数の値を知りたいの?」といったところでしょうか.続けて,「もしも本気ならば関数式のあとに『 _』を添えて下さい.」とも.
今も,c1を定義するにあたって,c(1) _と書きました.この_を抜かすとやはり以下のように同様のエラーになります.
scala> val c1 = c(1)
<console>:11: error: missing arguments for method c;
follow this method with `_' if you want to treat it as a partially applied function
val c1 = c(1)
^
つい,忘れがちなのですが,_のこと覚えておいて下さい.
なお,複数の引数をとる関数に対して,引数を一気に与えるかわりに,少しずつ与える形式に変換する操作をCurry化と呼びます.この名称は,数理論理学者のHaskell Brooks Curryにちなんでいます.Haskellあるいは,Curryを耳にしたことがないとしたら,情報科学の徒とは言えません.
val 項
以下の定義はvalを三回も使っているし,たいした定義でもないのに三行も消費していて,なんだか記述が冗長な気がします.
val c1 = c(1)(nums)
val c2 = c(2)(nums)
val c3 = c(3)(nums)val宣言が項に対するパターンマッチの機能を許しているので,以下のように簡潔に書き直すことができます.
val (c1, c2, c3) = (c(1)(nums), c(2)(nums), c(3)(nums))リスト処理の連打
以下のコードの意味がわかるでしょうか.リスト処理を満載しています.
def satisfy(candidate: List[Int]): Boolean = {
counts(candidate).zip(countsOnPaper).map(p => p._1 + p._2) == candidate
}
これは counts(candidate) = List(0, 1, 2, 3), countsOnPaper = List(2, 1, 2, 0) のとき,zip操作によって,これらのリストを項のリスト,すなわち List((0, 2), (1, 1), (2, 2), (3, 0)) にまとめあげ(やっていることがジッパーみたいでしょ),その結果にmap処理を施して,項の要素の和のリスト,すなわち List(0 + 2, 1 + 1, 2 + 2, 3 + 0) = List(2, 2, 4, 3) に変換しています.
ここで,項pのふたつの要素をp._1とp._2で参照しています.このようにp._nによって項から目的とする要素を簡単に取り出すことができます.
前節へ 章へ 次節へ